To get accurate speech-recognition results, the speech recognizer (Dragon) must be "taught" any new words or common sequences of words that you will speak. When coding or controlling the computer by voice, we use many words or phrases that are not in the common english lexicon.
The vocabulary package extends VoiceCode with several important features, and includes some basic default settings for each feature.
Individual vocabulary words
For simple words (or even short multiword phrases) that are not currently being recognized well, you can add them like this:
unboundmusic/45e489220ef0ad039b72897e8cd1b4e9
Vocabulary with alternate pronunciation
For words that are spoken significantly different than they are written, you can add vocabulary like this. This tells the speech recognizer that the pronunciation should be what is written on the left-hand side, while the actual word it should produce from that pronunciation is the right hand side. If individual letters need to be pronounced, make sure they are uppercased, as in "ES Six", and if numbers need to be spoken, they should be spelled out on the left-hand side.
unboundmusic/29ea6a670aef3a08b000673349c1fe70
Common command sequences (bigrams)
Sometimes when combining multiple commands into longer phrases, certain combinations of commands are not easily recognized by dragon, or when combined, two commands might accidentally sound more like a different word. To boost recognition, we can "teach" Dragon common word/command sequences. For each entry, the left-hand-side is a word or command ID, and the right-hand side is an array of words or command IDs that would commonly follow the command on the left.
unboundmusic/c84008af119a5b6048193697024e55ce
Since it is common to say any of the "alphabet letters" after the certain commands, we demonstrated adding all the alphabet letters above.
Hint: to get the full command id of any command just say @sherlock <command name>@ and it will type out the full name. For example @sherlock [email protected] will type `format:lower-no-spaces`
Translations
By "translations", we basically mean text substitutions. The substitution happens within VoiceCode, not within the speech recognizer. For example, if a word is commonly misspelled or formatted incorrectly by Dragon, it can be fixed on the VoiceCode side.
It's important to note that translations are applied before the string is processed by other commands that may use the text as a parameter for their action.
Take for example, the word "main". If you say the word by itself, it's most likely that Dragon will interpret it as "Maine". Or the phrase "et cetera", which you would probably want as "etc.". To fix these you could do:
unboundmusic/15fc77ee0f838671b2c8c87205ac0457
Creative uses of translations
For simple text substitution, translations can also be used as quasi-commands in cases where the action only needs to type out text. For example if a project you worked on has some variable names that get used a lot (maybe "locationId"), instead of having to use a formatting command to format that variable every time, you could add a translation:
unboundmusic/2289d4365371dff3cfb8902a6dc5b8b2
Or if there is a word you can just never get Dragon to recognize properly, maybe "null", you could do something like this, using a more easily recognizable word to substitute for the troublesome word.
unboundmusic/6c4c72f9a9619c0ad7c000922325814d
Dynamic Translations
Instead of providing just a string as the substitution value for a translation, you can also provide a function that can return any arbitrary value. For example:
unboundmusic/ff19ff020226ab0c23dbb8775f032c2b
Translation Scopes
Instead of having to duplicate logic that has already been used elsewhere to define a `Scope`, any existing scope can be applied to a translation, so that the translation will only happen if that scope is active.
Also, if multiple different scopes should return the same translation value, the key for that entry can be a comma separated list of scopes. Each value can be a string OR a function that returns a string
unboundmusic/9327a9e3f575251818e41372be1ad1f6
Dragon vocabulary files
VoiceCode auto generates some special files for importing into Dragon in order to increase recognition accuracy. They are located in `~/voicecode/generated/*.xml`. These files are regenerated every time you enable/disable commands or edit settings that affect vocabulary. After getting most of your commands set up you should import these files. You should also make a habit of importing them again from time to time as they greatly improve recognition accuracy. Depending on how much you are changing the grammar, importing once every several weeks is a good default.
Import vocab into Dragon
- Open the Dragon drop-down menu and select "Edit Vocabulary"
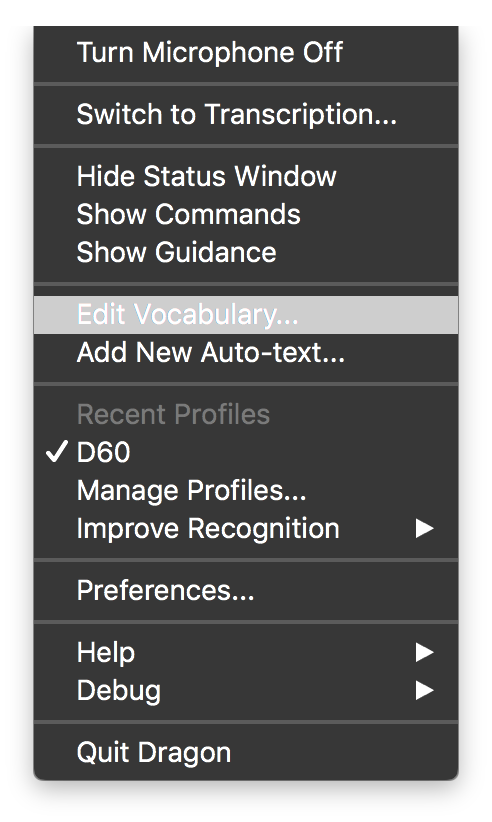
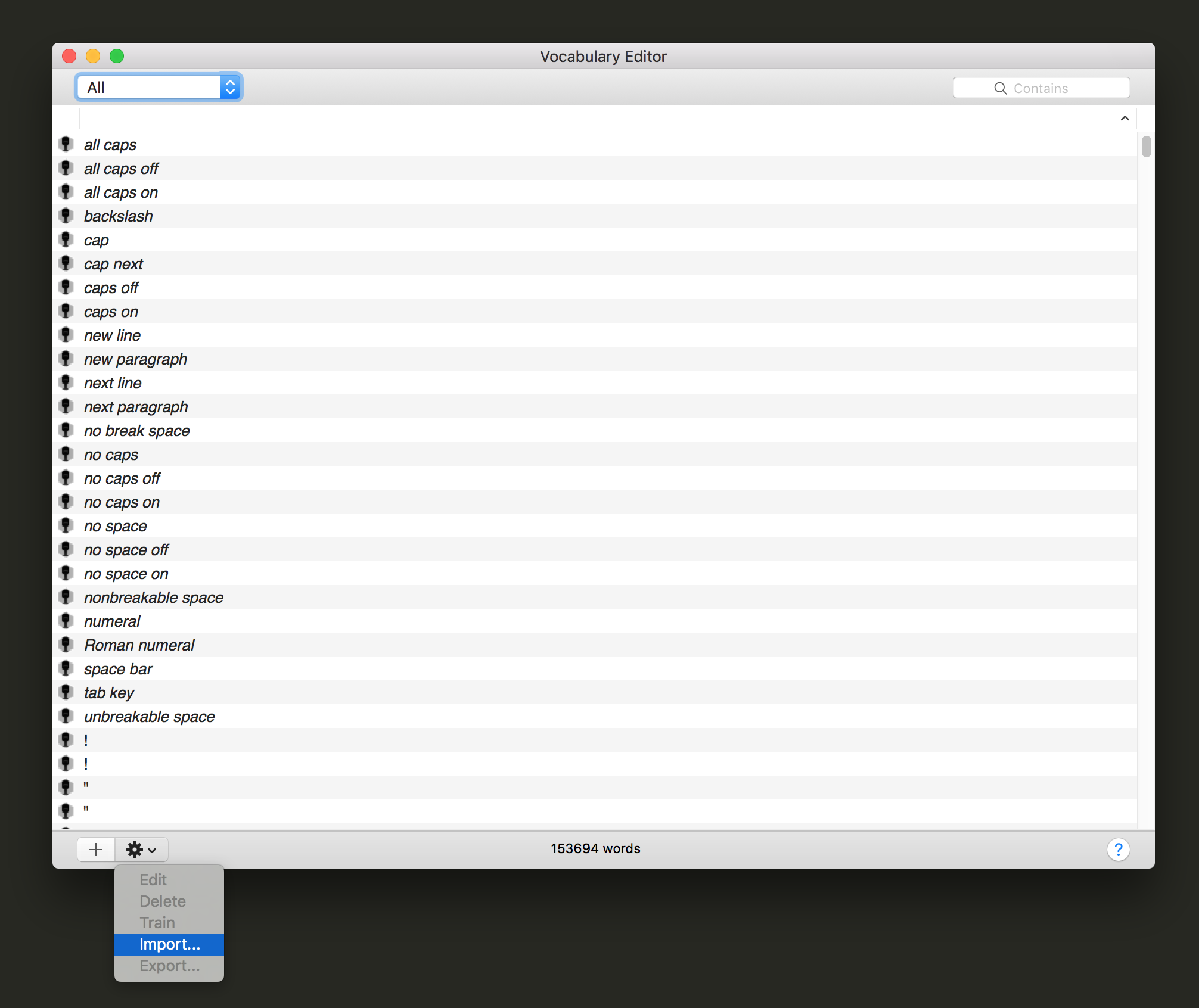
- Click on the "gear" icon, and choose "Import"
- Select the generated xml vocabulary files in the ~/voicecode/generated folder.
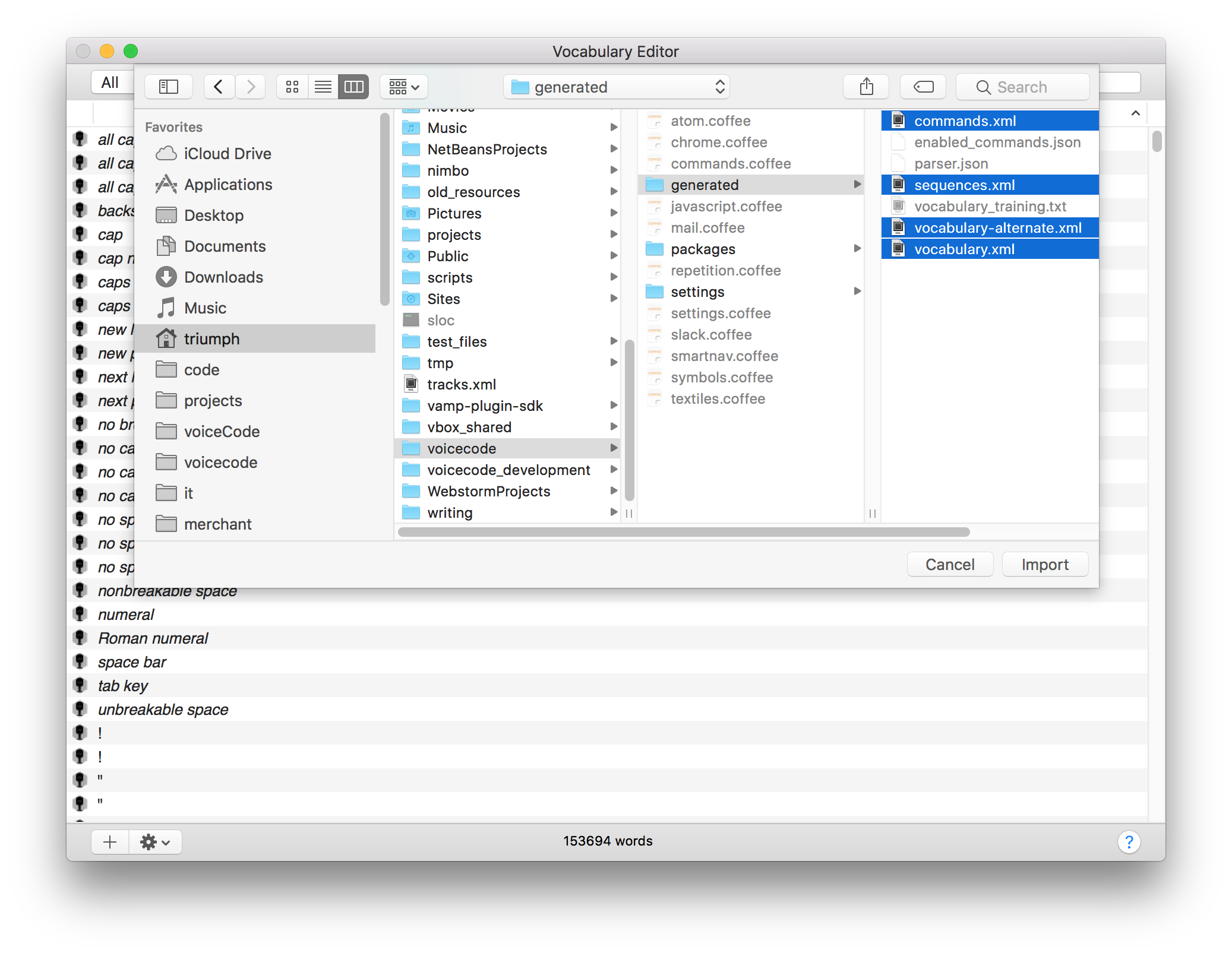
- Wait until the import finishes. Depending on your computer speed this could take up to 10 minutes or so on the first import. If it takes way too long, or Dragon crashes, repeat the steps but load a single xml vocabulary file at a time, instead of doing them all together.
Vocabulary Training (important)
This improves Dragon's recognition accuracy for added vocabulary and command words





